Evaluating Devin as a “Virtual Full-Stack Software Engineer”
George Marcel Leāo
March 16, 2026
Over the past few weeks, We have been running a pilot at Devblock to understand where AI —specifically Devin — can fit into our software development workflow. This post summarizes what we observed: where Devin shines, where it has limits, and what we should explore next. This is not a finished playbook; it’s a snapshot of an ongoing experiment.
Why Devin Is Interesting
Most AI coding tools we’ve tested run locally. They compete with everything else on our machine —Docker, the browser, IDEs—so complex tasks quickly become painful. Running multiple agents in parallel is often not realistic.
Devin takes a different approach:
It runs entirely in the cloud.
It uses its own compute, infrastructure, and environment.
It is not constrained by my laptop’s CPU, RAM, or battery.
It can run multiple sessions in parallel, each on its own cloud resources.
This seemingly small architectural choice is actually significant. It enables Devin to take on complex, long-running tasks without being bottlenecked by local hardware, and it makes “parallel virtual engineers” a practical reality.
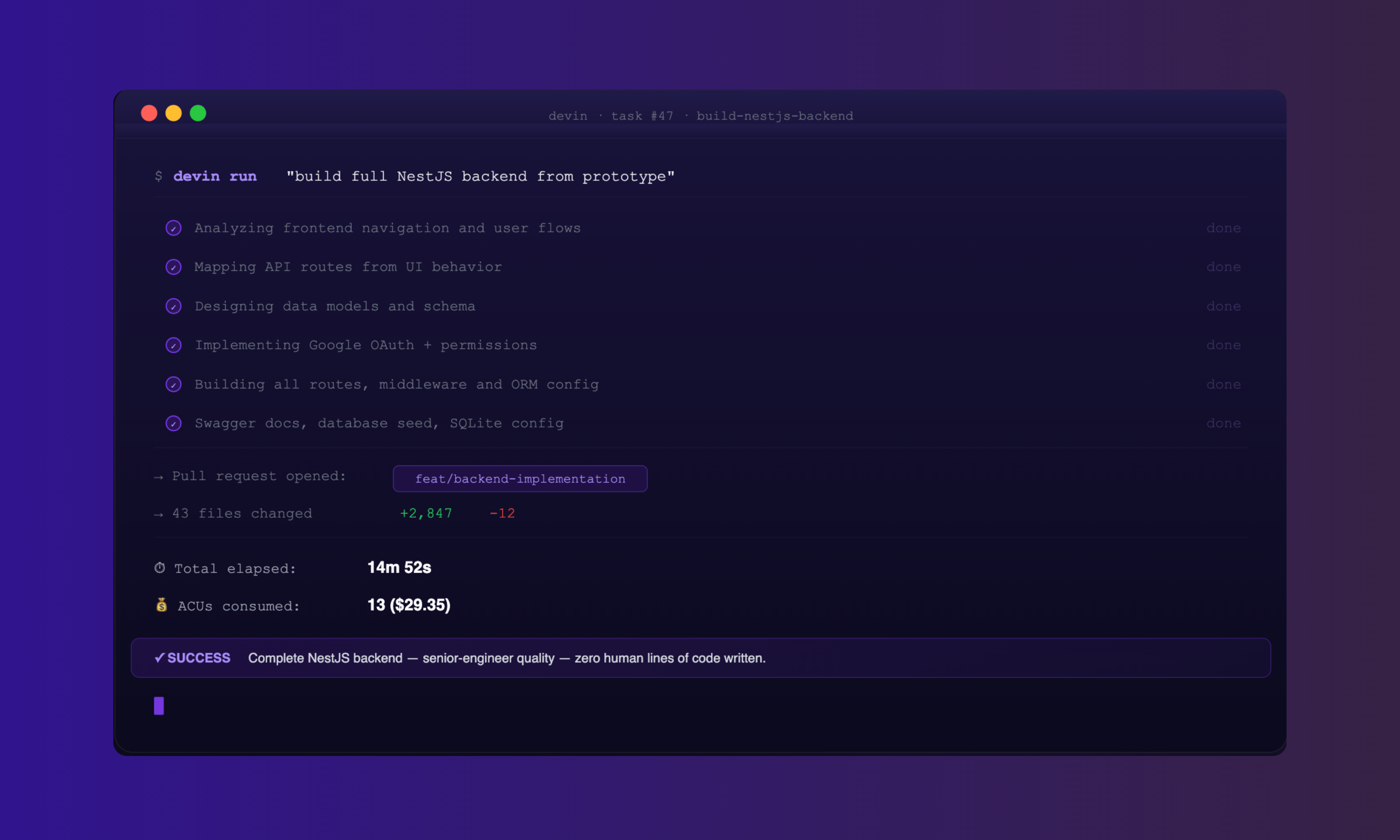
Test 1: Full-Stack Backend Implementation
For the first test, We asked Devin to build a full backend from a web prototype. The task included:
Analyzing the application navigation
Mapping required APIs from frontend behavior
Designing data models
Implementing Google authentication
Building a complete backend with SQLite for testing
Creating all routes with proper middleware
Enabling Swagger documentation
Configuring the ORM and seeding the database
In about 15 minutes, Devin opened a pull request containing:
A complete NestJS backend
Proper structure and layering
Authentication and permissioning
Seeded data and working routes
Documentation and configuration
The implementation quality was comparable to what we would expect from a senior engineer over several days of focused work. We also had Claude CLI review Devin’s output; its assessment was similarly positive.
Test 2: Cross-Stack Bug Fix With Context
In the second test, we wanted to see whether Devin could behave more like a full-stack engineer embedded in our workflow.
Setup:
We created a Jira task describing a document upload bug that spanned both frontend and backend.
Devin was connected to:
Jira (for tasks)
A dedicated Slack channel (for communication)
The code repository
Confluence (for contextual documentation)
End-to-end behavior:
Devin read the Jira task.
It accessed Confluence to understand prior context and decisions.
It analyzed the codebase to locate the relevant areas.
It implemented fixes across both frontend and backend.
It ran tests to validate the solution.
It opened a pull request with the changes.
It notified me in Slack that the PR was ready for review.
In practice, Devin behaved like a full-stack engineer who could:
Understand the task and surrounding context
Make coordinated changes across the stack
Communicate progress and completion via Slack
Our only input was the initial Jira ticket; everything else was autonomous.
Test 3: Data Architecture and Design
Next, We evaluated Devin in a more architectural role.
We asked Devin to:
Analyze a set of requirements
Propose a database model
Design API endpoints
Define security layers
Produce accompanying documentation
The result was:
A coherent data model
A well-structured API design
Clear security considerations
Written documentation that required minimal correction
For data architecture and system design at a medium scale, Devin produced a solid first draft that a human architect could refine rather than create from scratch.
The Economics: Cost Versus Value
To realistically evaluate Devin, we have to look at cost.
For the 15-minute backend implementation task described in Test 1:
Devin consumed ~13 ACUs (Agent Compute Units).
$29.35 was paid for those credits.
To put that in context:
One complex Devin task (15 minutes): ≈ $29.35
Significant tasks per month for a senior engineer: perhaps 20–40 (depending on complexity)
If Devin can execute ~20 tasks of similar complexity in a month at this rate:
20 tasks × $29.35 ≈ $587
Even if we double or triple that for variability and overhead, Devin is still an order of magnitude more efficient than a typical full-time senior engineer for pure execution of well-defined tasks.
However, there are important caveats:
Devin performs best with clear, well-specified requirements.
Human review and oversight are still required.
Devin does not attend meetings, negotiate tradeoffs, or reason about deep business context.
It does not replace engineers; it augments them.
A realistic model is hybrid:
Use humans for:
Discovery
Product and architectural decisions
High-ambiguity problem solving
Final validation
Use Devin primarily for:
Execution of well-defined tickets
Cross-stack bug fixes
Maintenance and small features
How Devin Compares to Other Approaches
We compared Devin with two alternative setups: using Claude via API with a local orchestrator, and running open-source models on our own infrastructure.
Approach
Cost per 15 min complex task
Infrastructure
Parallelization
Claude API + local orchestrator
$0.09 – $0.15
Local machine
Limited by local hardware
Self-hosted open source
$0.63 – $1.50 (at full utilization)
Our cloud
High (if we build and manage it)
Devin
~$2.25 per ACU (13 ACU = $29.35)
Devin’s cloud
Built-in, effectively unlimited
Key observations:
Claude API + local orchestrator Very cheap per task, but constrained by local machine resources. Parallel work and long-running jobs become operationally challenging.
Self-hosted open source More expensive than pure API calls but still economical if we can keep utilization high. However, this requires us to:
Provision and manage infrastructure
Build and maintain orchestration
Own reliability and scaling
Devin Most expensive per task, but:
Infrastructure is fully managed.
Parallelization is “baked in.”
Integrations (Jira, Slack, Confluence) are available out of the box.
In other words, Devin trades higher per-task cost for lower operational complexity and faster time-to-value.
The Integration Advantage
Unexpectedly, integrations turned out to be one of Devin’s strongest differentiators.
With Devin connected to:
Jira (tasks and workflow)
Slack (communication)
Code repository (source control)
Confluence (documentation and context)
We can start to imagine a new operational model, especially for consulting and maintenance work.
Example Scenario
We deliver a project to a client.
As part of the engagement, we provide a shared Slack channel for their product manager.
Devin is connected to:
That Slack channel
The project’s Jira board
The code repository
The product manager reports: “The document upload is failing for PDFs larger than 10MB.”
In an ideal Devin-driven workflow:
Devin reads the Slack message.
It creates a corresponding Jira task.
It investigates the codebase to identify the cause.
It implements and tests a fix.
It opens a pull request.
It posts an update in Slack for human review and approval.
With approval, it updates the environment (test and/or production).
From a client’s perspective, this is a virtual engineer on retainer:
Available to handle well-defined bugs and small features.
Cost aligned to ACUs per task instead of human hours.
Response times that could be faster and more consistent.
For us, this could change the nature of maintenance contracts:
Less about staffing individual engineers.
More about bundling “virtual engineer capacity” into ongoing agreements.
More predictable costs on both sides, especially for repeatable maintenance work.
Key Insights From the Pilot
After several weeks of experimentation, a few themes stand out:
Model quality varies significantly.
Claude Opus currently handles complex planning and multi-step reasoning better than most.
Grok can be useful for simpler bugs and direct code edits.
Gemini and GPT-based coding models sit somewhere in between. The gap in capability is noticeable, and model choice matters.
The specification matters more than the orchestrator.
Tools like Windsurf, Cursor, and Claude CLI can all be effective.
The real performance difference comes from:
How well we set up the context
How precisely we define the task
How cleanly we structure repos, docs, and environments
Devin is expensive per task but strong in outcome per task.
For ~$29.35, I got:
A complete backend implementation that would have taken days.
A cross-stack bug fix with full Jira + Slack integration.
The value density of each Devin task is high when the problem is well defined.
Cloud-native execution is the real unlock.
Devin runs on its own infrastructure.
It does not depend on my laptop or workstation.
It can:
Work on multiple tasks in parallel
Run for hours without interruption This is fundamentally different from every purely local setup I tested.
Client maintenance and support could be reimagined.
Bundling a “virtual engineer” into our proposals:
Increases perceived and actual ongoing value.
Potentially lowers costs for both parties.
Differentiates us from traditional “build and handoff” shops.
Open Questions
This is still early-stage exploration. Several important questions remain:
Scalability on large codebases How does Devin perform against very large, complex monoliths or polyrepos, as opposed to medium-sized projects?
Concurrency and conflict management What happens when multiple Devin sessions work on overlapping parts of the system? How do we prevent conflicting changes and ensure consistent state?
Human–AI division of labor Where is the right boundary between Devin and human engineers? Which tasks should we systematically assign to Devin versus humans?
Onboarding and team practices How do we train new team members to:
Write “AI-ready” tickets and specifications?
Collaborate effectively with Devin?
Review and validate AI-generated changes efficiently?
Answering these questions will determine how far we can safely scale this model.
Closing Thoughts
AI agents like Devin will not replace engineers at Devblock in the near term—but they are already capable of acting as high-leverage execution partners when:
The problem is well-scoped
The system is reasonably well structured
The surrounding integrations (Jira, Slack, Confluence, CI/CD) are in place
Our challenge is to design workflows, contracts, and team practices that take advantage of these capabilities without compromising quality, safety, or maintainability.
We are still early. The tools, models, and economics are evolving quickly. The most practical path forward is to:
Keep experimenting in controlled but realistic conditions
Share what we learn as a team
Build reusable knowledge and infrastructure that outlasts any single tool